TimeLine引擎
一种基于范围(如关注账号、关系圈,附近的人等)推送,范围里面的人发布各种内容,内容按照不同的组织形式展现的流。如将用户关注的账号的动态流或内容流整合后,按照时间等条件排序,显示成流状的形式。如:微淘,微博,朋友圈、订阅号等类似场景。
基本概念
feed:一条内容,如一条微博、朋友圈。
这里把Feed看做 Email,每个用户都有一个收件箱,每个公众号(或商家)都有一个发件箱。
Inbox收件箱:用户收到的内容箱子
Outbox发件箱:公众号(或商家)已发布的内容箱子
常见的Timeline模式
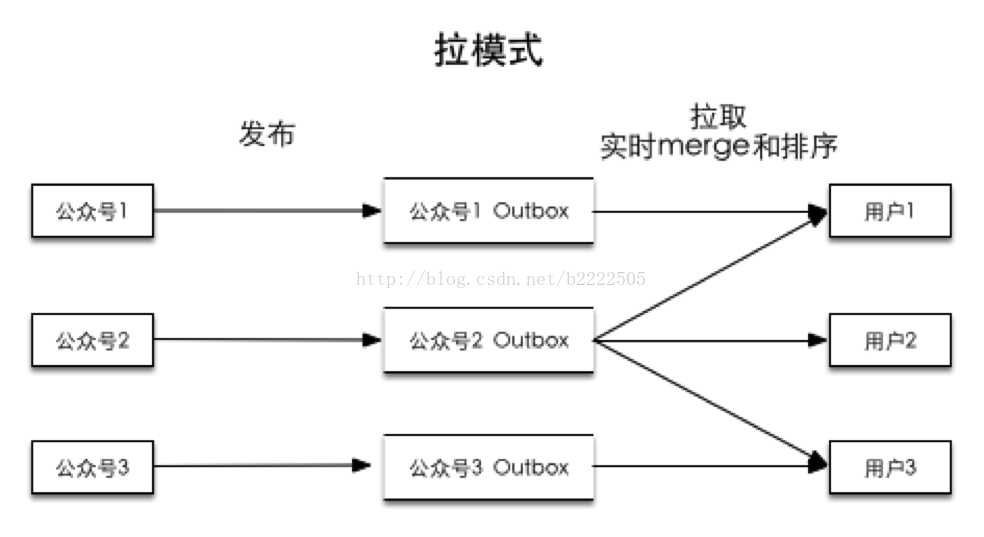
1、拉模式
发布:存到公众号(或商家)自己的Outbox(轻)
查看:所有关注公众号(或商家)的Outbox(重)
缺点:
只适用于天生基于稳定的账号关系(公众号-粉丝用户),无法支持如“个性化”和“广告”等“定向推送”的功能,比如,公众号就希望给某些用户推送Feed,而不管用户和公众号之间的关系。
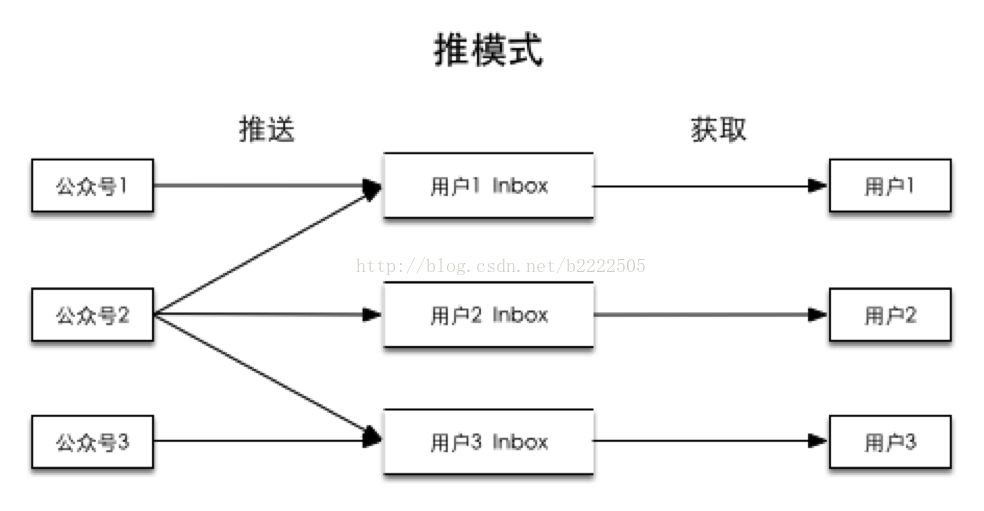
2、推模式
发布:存到所有关注自己的用户的Inbox(重)
查看:直接访问用户自己的Inbox(轻)
缺点:
拉模式以公众号outbox为维度存储,一条Feed只存一份索引信息;推模式以用户inbox为维度存储,一条Feed要存许多份索引信息,存储空间成倍增长。
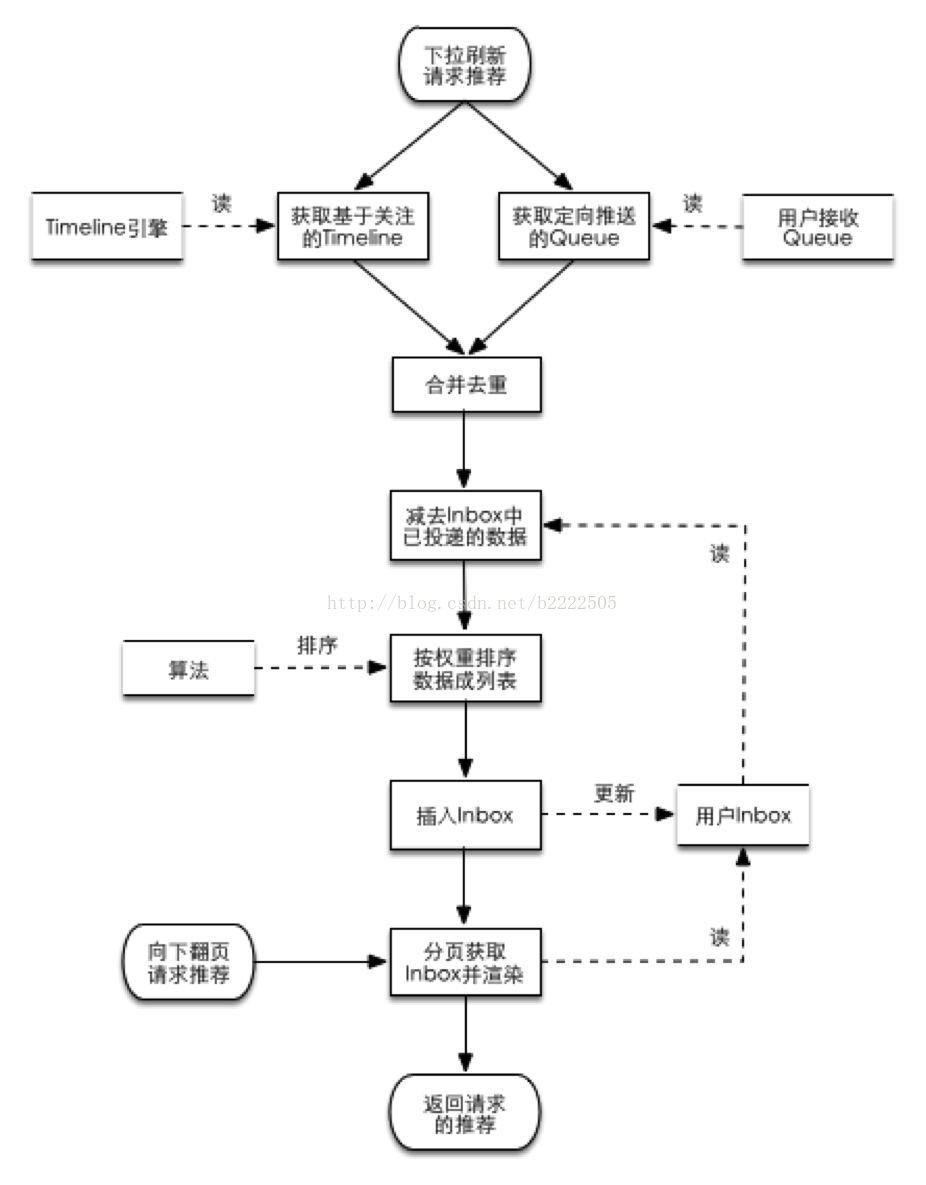
3、推拉模式结合
queue推送队列:每个用户有一个接收公众号(或商家)推送的队列queue,公众号(或商家)定向推送的内容就存储在该queue中。
inbox投递邮箱(跟最上面说的inbox不一样):每个用户有一个记录已经投递内容的邮箱inbox,内容包括拉的timeline和推的queue两部分,主要用于记录已经推送给客户端的数据,不会再被推送,且历史顺序稳定。
timeline系统参数
5-10ms
100多台机器
10万级别商家发件箱,存在热点数据,单机全量热点数据缓存。
多级缓存:本地堆外缓存(ohc、kv-v为list、98%命中率、lru)> tair(mdb) > DB(分库分表)
插入时失效缓存,查询时更新。
数据结构以索引为单位,可排序和过滤。
先排序(list自带sort)、过滤(ANTR表达式)、返回数据
如果文章对您有帮助,欢迎扫描下方二维码赞助(一分也是爱噢),谢谢

