简介
rocketMQ是一款分布式、队列模型的消息中间件。基于发布订阅模式,有Push和Pull两种消费方式,支持严格的消息顺序,亿级别的堆积能力,支持消息回溯和多个维度的消息查询。
核心作用:解耦、异步化、消息堆积缓冲
高性能离不开异步,异步离不开队列!
基本概念
- Producer: 消息生产者,负责产生消息并发送消息到meta服务器
- Consumer: 消息消费者,负责消费消息,一般是后台系统负责异步消费。
- Broker: Metaq的服务器。
- Topic: 消息的主题,由用户定义并在服务端配置
- Message: 在生产者,消费者,服务器间传递的消息
- Group: 消费者分组。消费者可以是多个消费者共同消费一个 topic 下的消息,每个消费者消费部分消息。这些消费者就组成一个分组,拥有同一个分组名称,通常也称为消费者集群。
- Offset: 消息在服务器上的每个分区都是组织成一个文件列表,消费者拉取数据需要知道数据在文件中的偏移量。
架构图
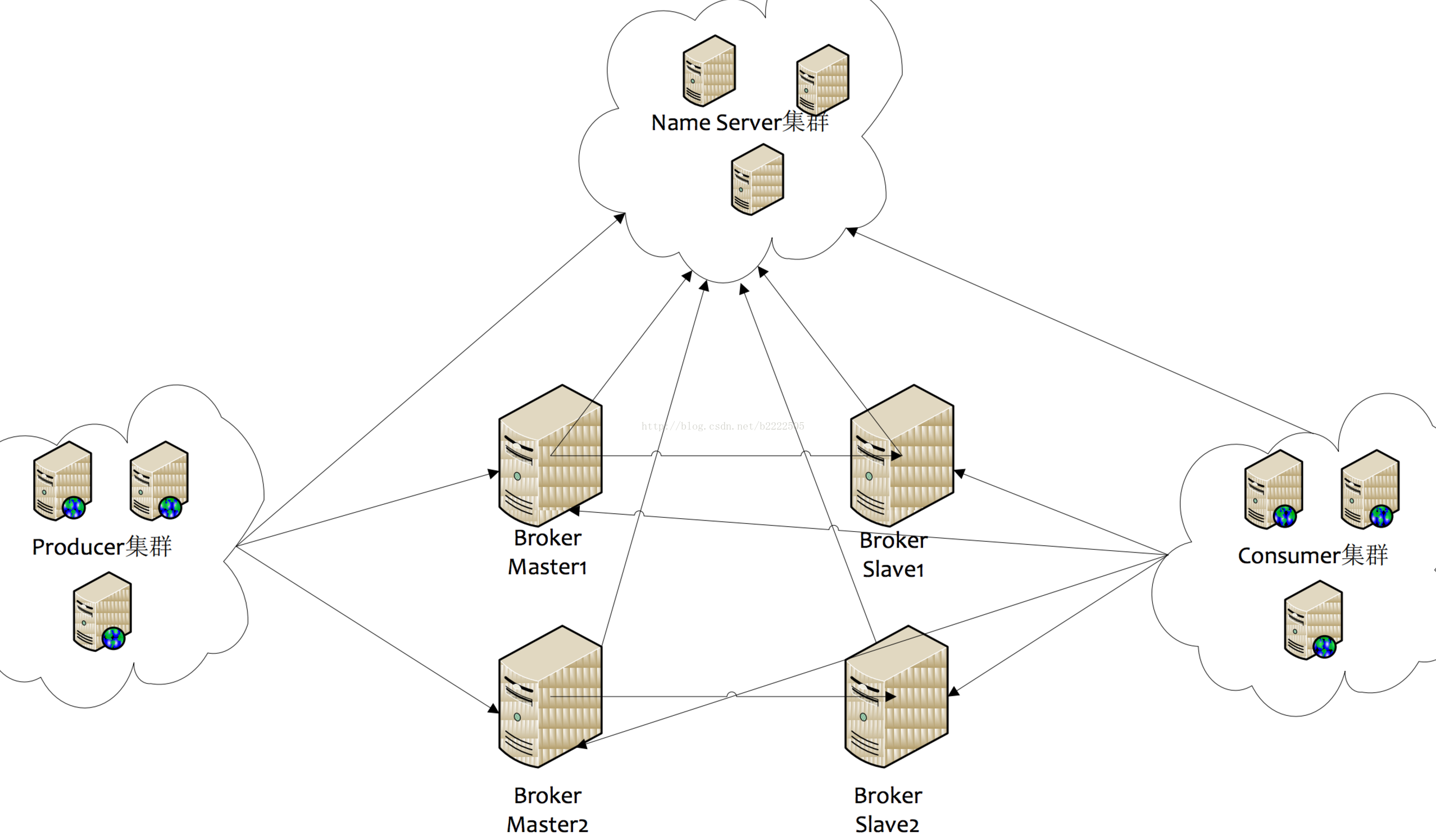
主要消费流程
1、Producer:生产者首先向NameService拉取Topic相关的所有Broker,然后以RobinRound方式发送消息。
2、Broker:消息进入Broker后,先写入CommitLog里。同时会将该消息在文件的物理位置,消息大小,消息类型封装成一个固定大小的数据结构,称为索引单元。然后异步写入到ConsumerQueue中。
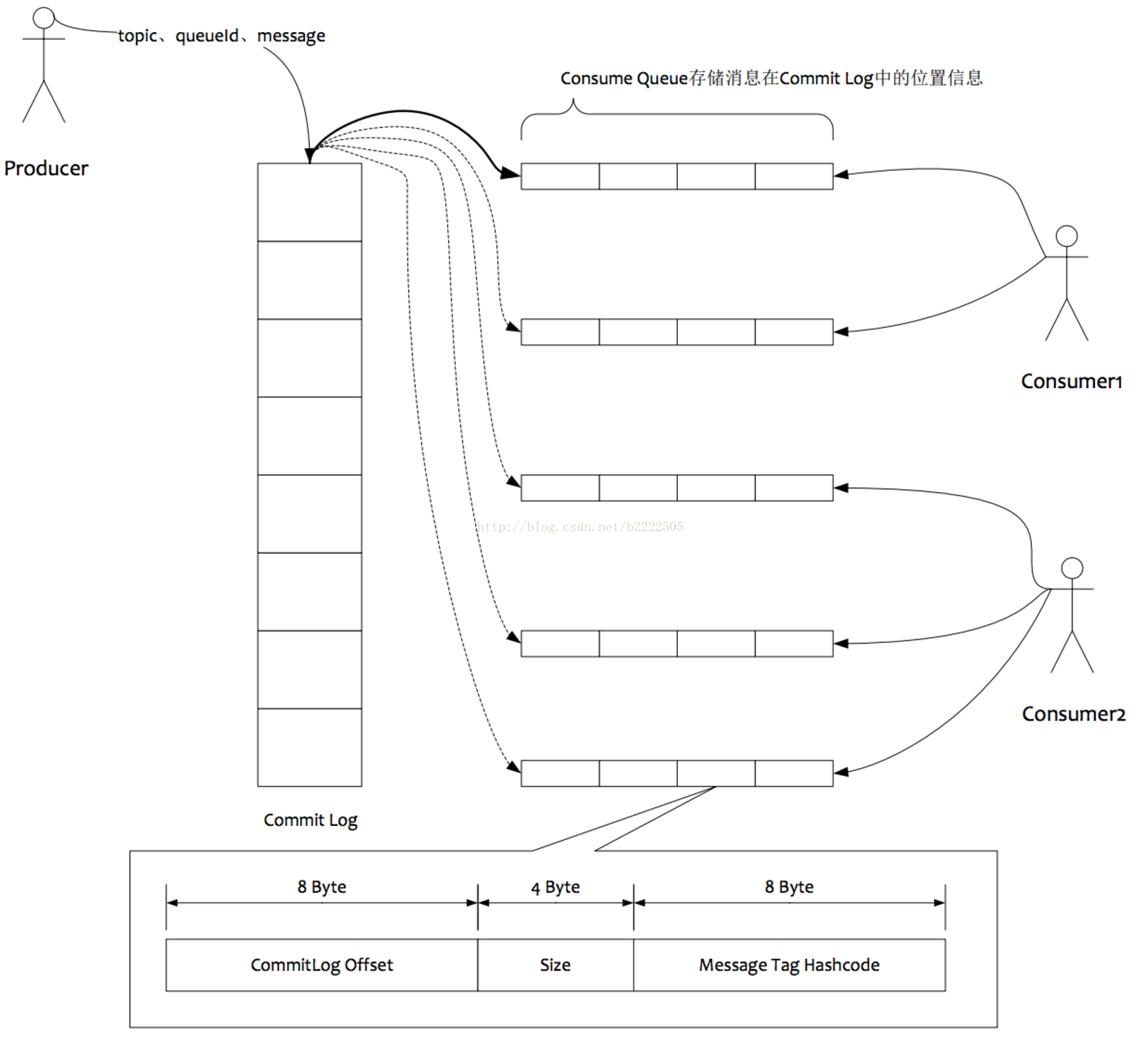
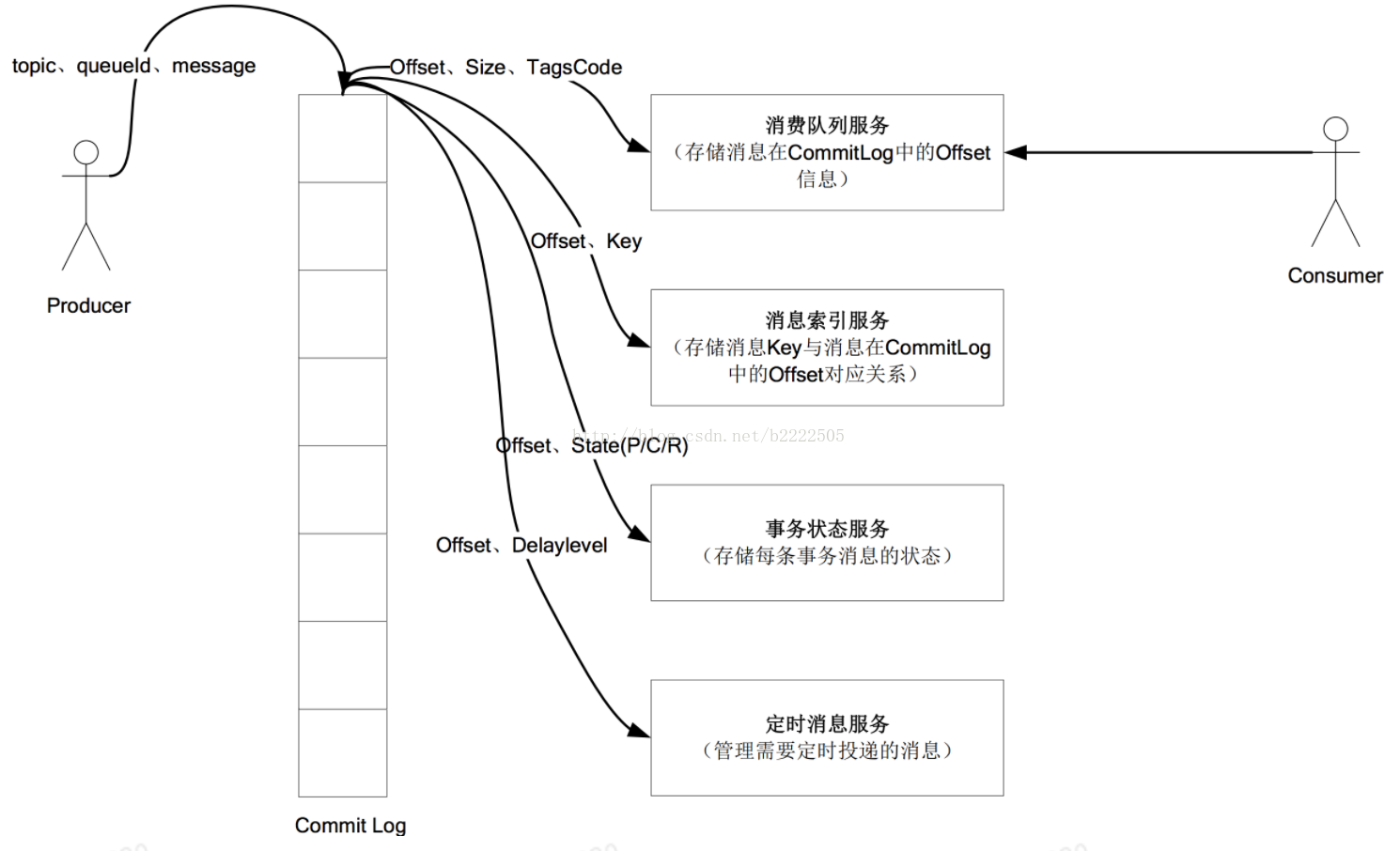
3、Consumer:消费者采取拉模式向一台Broker请求Topic信息,然后进行Reblance操作,计算自己负责的队列,然后消费。广播模式下消费进度存储在本地,单播模式下存储在Broker。
具体消费过程
消费端拉取消息时,至少需要以下几个参数
- 消息主题
- 逻辑队列序号
- 索引起始位置
- 消息最大长度
- 当前请求序列号
- 消费者分组名称
服务器收到请求后
- 根据 topic 和 partition 找到逻辑队列:A
- 根据 offset 从 A 定位指定的索引文件:B
- 从 B 中读取所有的索引数据:C
- 遍历 C,根据索引单元的消息物理地址和消息长度,找到物理消息 D(二分遍历),将 D 放入集合,并计算消息的累加长度,若大于请求里消息最大长度 maxSize,则终止遍历,返回结果。
消息结果里有当前批次消息的索引读取结束位置(offset),消费端会将当前 offset 。存储在本地,下次拉取消息时,要将结束位置作为参数放入消息拉取请求里。由于 metaq 是分布式结构,消费端和生产端的对应关系可能会经常变动,offset 不能仅仅只是保存到本地,必须保存在一个共享的存储里,比如zookeeper,数据库,或共享的文件系统。默认情况下,metaq 将offset及时保存在本地,并定时写入zookeeper。在某些情况下,会发生消息重复消费,比如某个 consumer 挂掉了,新的consumer将会接替它继续消费,但是 offset是异步存储的,可能新的 consumer 起来后,从zookeeper上拿到的还是旧的 offset,导致当前批次重复,产生重复消费。
负载均衡
一个逻辑分区实际上是一组索引文件。一个 topic 在一个 broker 上可以有多个逻辑分区,默认为 1,但可自由配置。
一个topic可以分布在多台broker上,具体体现就是多个broker配置了这个topic,并且最少有一个分区。假如有一个topic名为”t1”,两个broker:b1,b2;每个 borker 都为 t1 配置了两个分区。那么 t1 一共有4个分区:b1-1,b1-2,b2-1,b2-2。生产者和消费者对topic发布消息或消费消息时,目的地都是以分区为单位。当一个topic消息量逐渐变大时,可以将 topic 分布在更多的 borker 上。某个 broker上的分区数越多,意味着该 borker承担更繁重的任务,分区数可以认为是权重的表现形式。
生产者负载均衡
生产者在通过 zk 获取分区列表之后,会按照 brokerId 和分区号的顺序排列组织成一个有序的分区列表,发送的时候按照从头到尾循环往复的方式选择一个分区来发送消息(可通过实现PartitionSelector接口改写负载均衡算法)
在broker 因为重启或者故障等因素无法服务的时候,producer 通过 zookeeper 会感知到这个变化,将失效的分区从列表中移除。从故障到感知变化有一个延迟,可能在那一瞬间会有部分的消息发送失败。
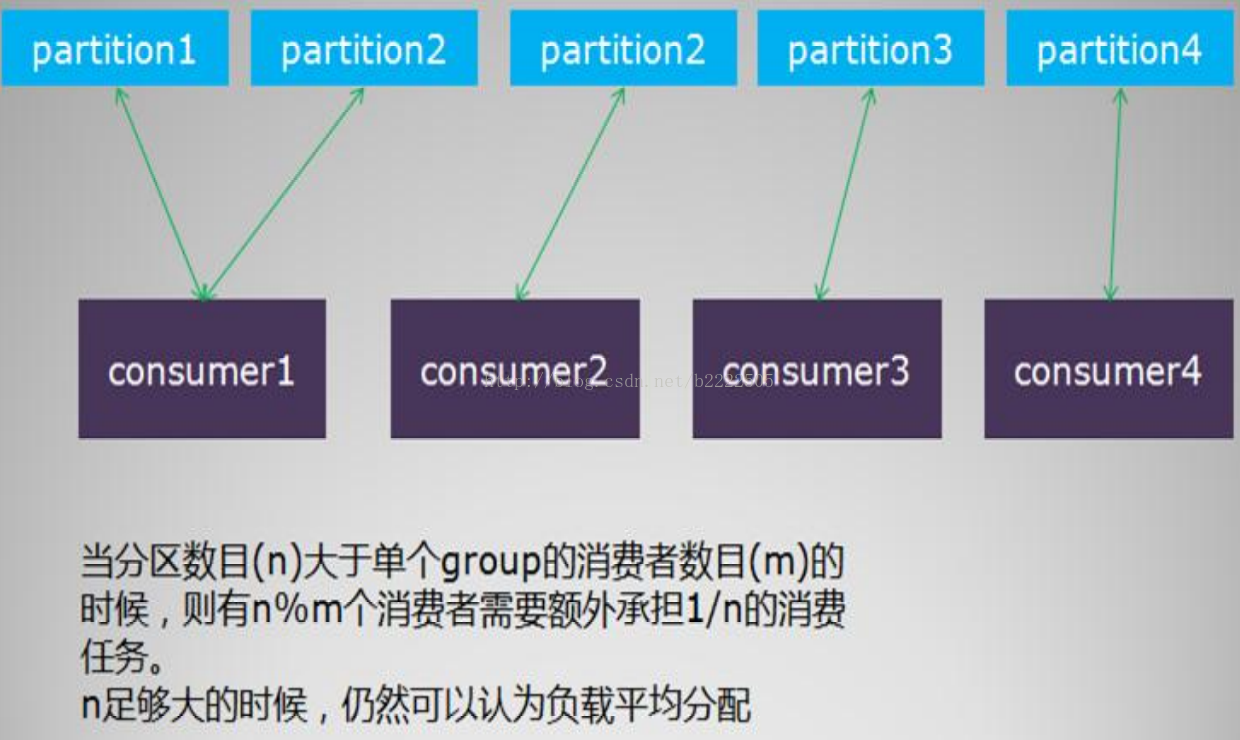
消费者负载均衡
单个分组内的消费者数目如果比总的分区数目多的话,则多出来的消费者不参与消费
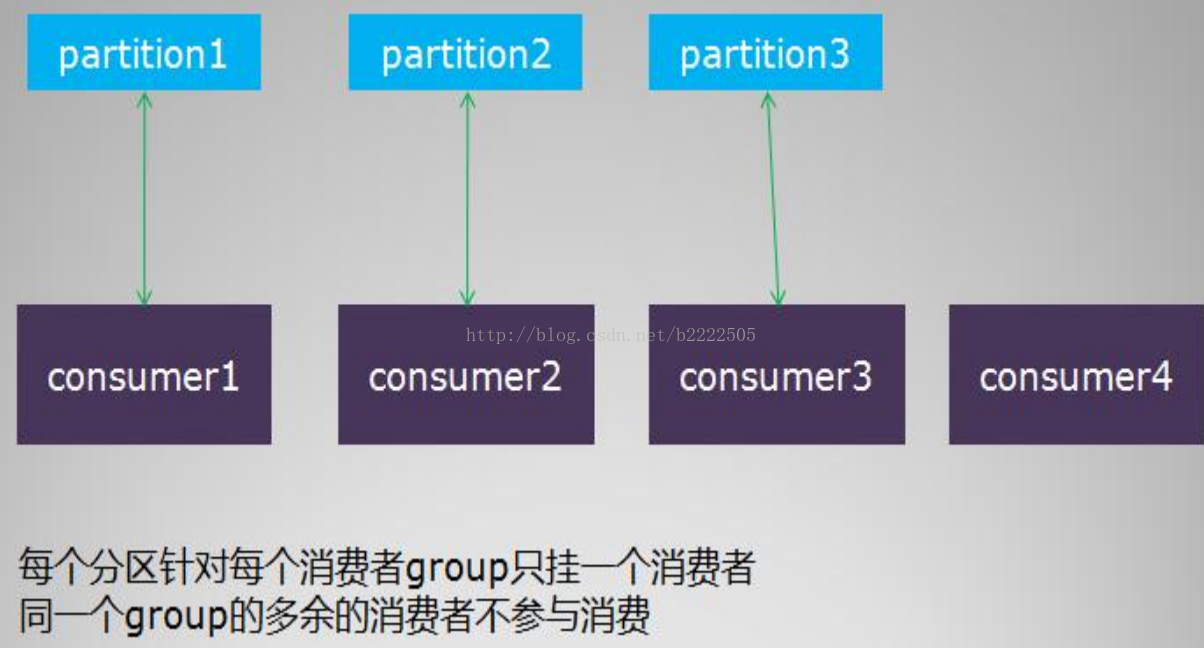
如果分组内的消费者数目比分区数目小,则有部分消费者要额外承担消息的费任务
性能问题
commit-log队列采取顺序添加的方式(200M 每秒),对磁盘的访问串行化,避免磁盘竟争(但是读却变成了完全的随机读,不过可以通过PAGECACHE优化掉)。
前面说的队列存储都是保存到文件中,频繁的IO操作会降低性能。通过把文件的内容被映像到计算机虚拟内存的一块区域(mmap),这样就可以直接操作内存当中的数据而无需操作的时候每次都通过 I/O 去物理硬盘读取文件,从而效率上有很大的提升。
修改不一定会立即同步到文件系统中。如果在没有同步之前发生了程序错误,可能导致所做的修改丢失。因此,在执行完某些重要文件内容的更新操作之后,应该调用相应方法来强制要求把这些更新同步到底层文件中
metaq 的消费模型是拉模式。而且拉取完一批消息,消费完毕,再去拉取下一批,而不是一条一条拉取,这里存在实时性和性能的权衡。
当消息堆积时,1K 大小左右消息体堆积情况下吞吐量非常高,在 5W 每秒以上。4K 消息性能最差,1W 每秒左右。
可靠性保证
生产者发送消息后返回 SendResult,如果 isSuccess 返回为 true,则表示消息已经确认发送到服务器并被服务器接收存储。整个发送过程是一个同步的过程。保证消息送达服务器并返回结果。
服务器收到后在做必要的校验和检查之后的第一件事就是写入磁盘(这里只是写入了系统缓存,存在缓存到磁盘的刷新过程),写入成功之后返回应答给生产者。
数据过滤
MetaQ支持两种过滤方式:服务器端过滤,客户端过滤。
服务器过滤:减少网络上无用消息的传输,但是会增加服务器负担。
客户端过滤:根据客户端需求来定制消息,缺点是很多无用消息都会传到客户端,如果客户端无法负载这么多消息就会导致故障问题。
如果文章对您有帮助,欢迎扫描下方二维码赞助(一分也是爱噢),谢谢

