网络质量需要根据历史数据来预测未来的结果,以指导最优点的选择,所以需要一个合理的预测算法。下面来简单介绍下解决方案。
移动平均预测
以历史7天的数据求平均值。存在下面的问题
- 保存的历史数据较多,计算速度较慢。
- 所有数据同等看待。
- 对于海外或者中小运营商,7天的总样本很小。
SRTT预测
令SRTT = St, R’ = Yt, alpha = α,则RTT平滑过程可以描述为:
St = α Yt + (1 - α)St-1, 其中α = 1/8
假设时间序列为Y1, Y2,…, Yt …, 则一次指数平滑公式为:
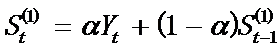
其中St为第t周期的一次指数平滑值,α为加权系数,0 < α < 1 。
将上述公式依次展开:
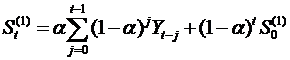
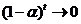 ,于是上述公式变为:
,于是上述公式变为:
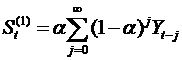
由于0 < α < 1,当t趋于无穷时,由此可见St实际上是Yt,Yt-1, …, Yt-j, …的加权平均。加权系数分别为α, α(1-α), α(1-α)2,…, 是按几何级数衰减的,越近的数据权数越大,越远的数据权数越小,且权数之和等于1,即 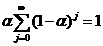
其中初始平滑值S0(1)可以取第一个序列或者前3个序列的平均值。
优势
- 可以将历史上所有的数据用起来,不存在选择多少天数据的问题,同时解决了中小和海外运营商的小样本问题
- 仅需要存储最近一期的真实数据及预测值,无需保留历史上的数据,计算速度快。
- 越近的数据权重越大,相对移动平均预测更快地反应了网络的变化
- α取值越大,表示越注重近期数据影响,如果序列变化比较平稳或者不规则波动(毛刺),α应该取小一些以消除不规则变化的影响;如果序列变化有明显的趋势,则α应该取较大值,近期数据占有更大的权重,可以较快跟上变化的趋势。
如果文章对您有帮助,欢迎扫描下方二维码赞助(一分也是爱噢),谢谢

