02-一切都是对象
将一切都“看作”对象,操纵的标识符实际是指向一个对象的“句柄”。 可将这一情形想象成用遥控板(句柄)操纵电视机(对象)。
String s;//这里创建的只是句柄,并不是对象。若此时向s 发送一条消息,就会获得一个错误.这是由于s 实际并未与任何东西连接(即“没有电视机”)。
一种更安全的做法是:创建一个句柄时,记住无论如何都进行初始化(创建句柄时,我们希望它同一个对象连接): String s = “asdf”;
new 将对象置于“堆”里。 主类型(基础类型),置于栈中。
- boolean 1 位 - - Boolean
- char 16 位 Unicode 0Unicode 2 的 16 次方-1 Character
- byte 8 位 -128 +127Byte
- short 16 位 -2 的 15 次方 +2 的 15 次方-1 Short)
- int 32 位 -2 的 31 次方 +2 的 31 次方-1 Integer
- long 64 位 -2 的 63 次方 +2 的 63 次方-1 Long
- float 32 位 IEEE754IEEE754 Float
- double 64 位 IEEE754IEEE754 Double
- Void - - - Void
主数据类型也拥有自己的“封装器”( wrapper)类
- BigInteger 支持任意精度的整数
- BigDecimal 支持任意精度的定点数字
创建对象数组时,实际创建的是一个句柄数组。而且每个句柄都会自动初始化成一个特殊值,并带有自己的关键字: null(空)。
创建主类型数组。编译器能够担保对它的初始化,会将数组内存划分成零。
每个Java 文件自动导入:java.lang
03-控制程序流程
equals()实际比较的是对象的内容,而非它们的句柄
>>>使用了“零扩展”:无论正负,都在高位插入0
04-初始化和清除
若创建一个没有构建器的类,则编译程序会帮我们自动创建一个默认构建器。若有,则不会生成默认构造函数。
“固有方法”是从Java 里调用非Java方法的一种方式。 C 和 C++是目前唯一获得固有方法支持的语言。在非 Java 代码内部,也许能调用 C 的malloc()系列函数,用它分配存储空间。而且除非调用了free(),否则存储空间不会得到释放,从而造成内存“漏洞”的出现。当然,free()是一个 C 和 C++函数,所以我们需要在finalize()内部的一个固有方法中调用它。
static初始化只有在必要的时候才会进行(在创建了第一个对象的时候或者发生了第一次 static 访问的时候)
在这里有必要总结一下对象的创建过程。请考虑一个名为 Dog 的类:
- 类型为 Dog 的一个对象首次创建时,或者 Dog 类的 static 方法/static 字段首次访问时, Java 解释器必须找到Dog.class(在事先设好的类路径里搜索)。
- 找到 Dog.class 后(它会创建一个 Class 对象),它的所有 static 初始化模块都会运行。因此, static 初始化仅发生一次——在 Class 对象首次载入的时候。
- 创建一个 new Dog()时, Dog 对象的构建进程首先会在内存堆( Heap)里为一个 Dog 对象分配足够多的存储空间。
- 这种存储空间会清为零,将 Dog中的所有基本类型设为它们的默认值(零用于数字,以及 boolean 和char 的等价设定)。
- 进行字段定义时发生的所有初始化都会执行。
- 执行构建器。这实际可能要求进行相当多的操作,特别是在涉及继承的时候。
05-隐藏实施过程
为 Java 创建一个源码文件的时候,它通常叫作一个“编辑单元”(有时也叫作“翻译单元”)。
每个编译单元都必须有一个以.java 结尾的名字。
在编译单元的内部,可以有一个公共( public)类,它必须拥有与文件相同的名字(包括大小写形式,但排除.java 文件扩展名)。如果不这样做,编译器就会报告出错。
每个编译单元内都只能有一个 public 类(同样地,否则编译器会报告出错)。
那个编译单元剩下的类(如果有的话)可在那个包外面的世界面前隐藏起来,因为它们并非“公共”的(非public)。
编译一个.java 文件时,我们会获得一个名字完全相同的输出文件。
对于.java 文件中的每个类,它们都有一个.class 扩展名。因此,我们最终从少量的.java 文件里有可能获得数量众多的.class 文件。
一个有效的程序就是一系列.class 文件,它们可以封装和压缩到一个 JAR 文件里。 Java 解释器负责对这些文件的寻找、装载和解释。
有一个编译单元根本没有任何公共类。此时,可按自己的意愿任意指定文件名。
不指定访问指示符,通常称为“友好”( Friendly )访问。这意味着当前包内的其他所有类都能访问“友好的”成员,但对包外的所有类来说,这些成员却是“私有”( Private)的,外界不得访问(对于包的用户来说,是不能访问一个“友好”成员的)。也说友好元素拥有“包访问”权限。
位于相同的目录中,而且没有明确的包名。 Java 把象这样的文件看作那个目录“默认包”的一部分,所以它们对于目录内的其他文件来说是“友好”的。
06-类再生
protected本身是私有的,但可由从这个类继承的任何东西或者同一个包内的其他任何东西访问。
上溯造型肯定是安全的,因为我们是从一个更特殊的类型到一个更常规的类型。
对于基本数据类型, final 会将值变成一个常数。 对于对象句柄, final 会将句柄变成一个常数。进行声明时,必须将句柄初始化到一个具体的对象。而且永远不能将句柄变成指向另一个对象。然而,对象本身是可以修改的。
Static 强调它们只有一个;而final 表明它是一个常数。
对 final 进行赋值处理—— 要么在定义字段时使用一个表达式,要么在每个构建器中。
final 方法不可被覆盖或改写。 一个方法设成 final 后,编译器就可以把对那个方法的所有调用都置入“嵌入”调用里
整个类都是 final表明自己不希望被继承。。 一个 final 类中的所有方法都默认为 final。
final方法可有效地“关闭”动态绑定,或者告诉编译器不需要进行动态绑定。
07-多形性
过载”是指同一样东西在不同的地方具有多种含义;而“覆盖”是指它随时随地都只有一种含义,只是原先的含义完全被后来的含义取代了(覆盖可以理解为继承多态)。
接口也包含了基本数据类型的数据成员,但它们都默认为 static 和 final。 接口的方法必须定义成public。
第一个选择就是把它变成一个接口。只有在必须使用方法定义或者成员变量的时候,才应考虑采用抽象类。
匿名类不能拥有一个构建器。
return new Contents() {
private int i = 11;
public int value() { return i; }
};
这种奇怪的语法要表达的意思是:“创建从 Contents 衍生出来的匿名类的一个对象”。由 new 表达式返回的 句柄会自动上溯造型成一个 Contents 句柄。匿名内部类的语法其实要表达的是:
class MyContents extends Contents {
private int i = 11;
public int value() { return i; }
}
return new MyContents();
一个实例初始化模块就是一个匿名内部类的构建器。
创建自己的内部类时,那个类的对象同时拥有指向封装对象(这些对象封装或生成了内部类)的一个链接,内部类拥有对封装类所有元素的访问权限。
C++“嵌套类”只是一种单纯的名字隐藏机制。
为创建一个 static 内部类的对象,我们不需要一个外部类对象。 不能从 static 内部类的一个对象中访问一个外部类对象。
Parcel11.Contents c = p.new Contents();
除非已拥有外部类的一个对象,否则不可能创建内部类的一个对象。这是由于内部类的对象已同创建它的外部类的对象“默默”地连接到一起。然而,如果生成一个static 内部类,就不需要指向外部类对象的一个句柄。
这意味着对于一个复杂的对象,构建器的调用遵照下面的顺序:
- 调用基础类构建器。这个步骤会不断重复下去,首先得到构建的是分级结构的根部,然后是下一个衍生类,等等。直到抵达最深一层的衍生类。
- 按声明顺序调用成员初始化模块。
- 调用衍生构建器的主体
在构建器内唯一能够安全调用的是在基础类中具有final 属性的那些方法(也适用于 private 方法,它们自动具有final 属性)
08-对象的容纳
java.util.*
数组标识符实际都是指向真实对象的一个句柄。那些对象本身是在内存“堆”里创建的。
对象数组容纳的是句柄,而基本数据类型数组容纳的是具体的数值
不可知道那个数组里实际包含了多少个元素,因为 length 只告诉我们可将多少元素置入那个数组。
集合类只能容纳对象句柄。但对一个数组,却既可令其直接容纳基本类型的数据,亦可容纳指向对象的句柄。
Stack“属于”一种 Vector
为了在散列表中将自己的类作为键使用,必须同时覆盖 hashCode()和 equals()
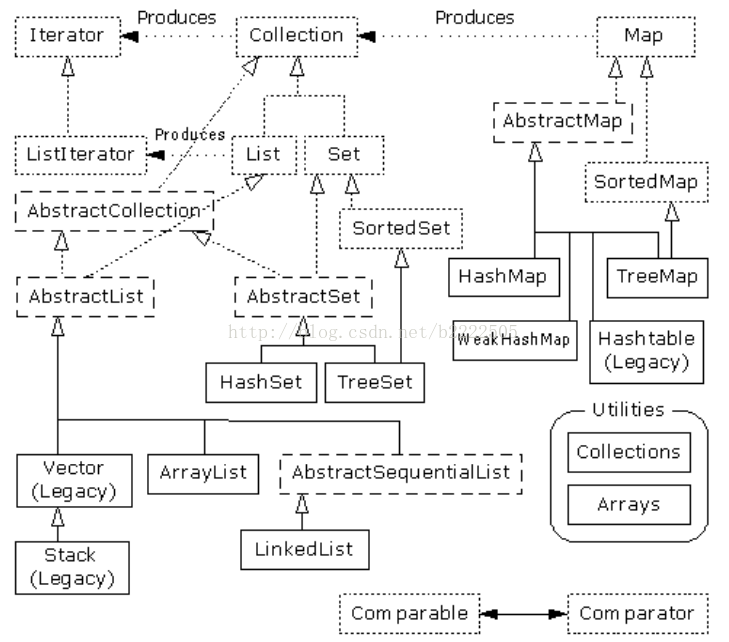
先选择一个 ArrayList 作为自己的默认起点。以后若发现由于大量的插入和删除造成了性能的降低,再考虑换成 LinkedList 不迟。
一般编写程序的时候,几乎永远用不着使用 ArraySet。推荐使用HashSet。
首要的选择应该是 HashMap。只有在极少数情况下才需要考虑其他方法。
- sort(List)用于对一个实现了Comparable 的对象列表进行排序;
- binarySearch(List,Object)用于查找列表中的某个对象;
- sort(List,Comparator)利用一个“比较器”对一个列表进行排序;
- binarySearch(List,Object,Comparator)则用于查找那个列表中的一个对象
- 当没有被排序对象的源码时只能使用Comparator。
Collection c =Collections.synchronizedCollection(newArrayList());
List list = Collections.synchronizedList(newArrayList());
Set s = Collections.synchronizedSet(new HashSet());
Map m = Collections.synchronizedMap(new HashMap());
09-违例差错控制
java.lang.Exception
对于Java 的违例控制机制,它的一个好处就是允许我们在一个地方将精力集中在要解决的问题上,然后在另一个地方对待来自那个代码内部错误。
void f() throws tooBig, tooSmall, divZero
RuntimeException可能从任何地方掷出,不用刻意说明
假若方法造成了一个违例,但没有对其进行控制,编译器会侦测到这个情况,并告诉我们必须控制违例,或者指出应该从方法里“掷”出一个违例规范。
void printStackTrace()打印出 Throwable 和调用堆栈路径。
throw e.fillInStackTrace();会生成一个 Throwable对象的句柄。调用栈从现在开始(或者重新throw newnewExction())
若对一个空句柄发出了调用, Java 会自动产生一个NullPointerException 违例。
我们没必要专门写一个违例规范,指出一个方法可能会“掷”出一个 RuntimeException,因为已经假定可能出现那种情况。
假若一个 RuntimeException 获得到达 main()的所有途径,同时不被捕获,那么当程序退出时,会为那个违例调用 printStackTrace()。
覆盖一个方法时,只能产生已在方法的基础类版本中定义的违例(相当于子类只能减少违例,比如不产生违例了)否则的话,当我们操作基础类时,便根本无法知道自己捕获的是否正确的东西。
衍生类构建器必须在自己的违例规范中声明所有基础类构建器违例(跟上面相反)。
若调用了 break 和 continue 语句, finally 语句也会得以执行。
用违例做下面这些事情:
- 解决问题并再次调用造成违例的方法。
- 平息事态的发展,并在不重新尝试方法的前提下继续。
- 计算另一些结果,而不是希望方法产生的结果。
- 在当前环境中尽可能解决问题,以及将相同的违例重新“掷”出一个更高级的环境。
- 在当前环境中尽可能解决问题,以及将不同的违例重新“掷”出一个更高级的环境。
- 中止程序执行。
- 简化编码。若违例方案使事情变得更加复杂,那就会令人非常烦恼,不如不用。
- 使自己的库和程序变得更加安全。这既是一种“短期投资”(便于调试),也是一种“长期投资”(改善应用程序的健壮性)
10-JavaIO系统
import java.io.*
与输入有关的所有类都从 InputStream 继承,而与输出有关的所有类都从 OutputStream 继承
java 1.0 io
import java.io.*;
public class InFile extends DataInputStream \{
public InFile(String filename) throws FileNotFoundException {
super(new BufferedInputStream(new FileInputStream(filename)));
}
public InFile(File file) throws FileNotFoundException {
this(file.getPath());
}
}
public class PrintFile extends PrintStream {
public PrintFile(String filename) throws IOException {
super(new BufferedOutputStream(new FileOutputStream(filename)));
}
public PrintFile(File file) throws IOException {
this(file.getPath());
}
}
public class OutFile extends DataOutputStream {
public OutFile(String filename) throws IOException {
super(new BufferedOutputStream(new FileOutputStream(filename)));
}
public OutFile(File file) throws IOException {
this(file.getPath());
}
}
System.out 进行标准输出,它已预封装成一个 PrintStream 对象。 System.err 同样是一个 PrintStream。
System.in 是一个原始的InputStream,未进行任何封装处理
一个 JAR 文件由一系列采用 Zip 压缩格式的文件构成,同时还有一张“详情单”,对所有这些文件进行了描述。
对一个 Serializable(可序列化)对象进行重新装配的过程中,不会调用任何构建器(甚至默认构建器)。
恢复了一个序列化的对象后,如果想对其做更多的事情,必须保证JVM 能在本地类路径或者因特网的其他什么地方找到相关的.class 文件。
Serializable(可序列化)对象完全以它保存下来的二进制位为基础恢复,不存在构建器调用。 而对一个Externalizable 对象,所有普通的默认构建行为都会发生(包括在字段定义时的初始化),而且会调用readExternal()。
transient 关键字只能伴随Serializable 使用。
只要将所有东西都序列化到单独一个数据流里,就能恢复获得与以前写入时完全一样的对象网,不会不慎造成对象的重复。
所以假如想序列化static 值,必须亲自动手。这正是 Line 中的 serializeStaticState()和deserializeStaticState()两个 static 方法的用途。
11-运行期类型鉴定
RTTI 的意义所在:在运行期,对象的类型会得到鉴定。
“ Class 对象”其中包含了与类有关的信息(有时也把它叫作“元类”),保存在一个完全同名的.class 文件中。
在运行期,一旦我们想生成那个类的一个对象,用于执行程序的 Java 虚拟机( JVM)首先就会检查那个类型的 Class 对象是否已经载入。若尚未载入, JVM 就会查找同名的.class 文件,并将其载入。所以 Java 程序启动时并不是完全载入的,这一点与许多传统语言都不同。
Class.forName("Gum");
Gum.class;//效果同上
Class.getInterfaces 方法会返回 Class 对象的一个数组,用于表示包含在 Class 对象内的接口。
用 newInstance()创建的类必须有一个默认构建器。没有办法用 newInstance()创建拥有非默认构建器的对象。然而,Java 1.1 的“反射” API)却允许我们动态地使用类里的任何构建器
编译器必须明确知道 RTTI 要处理的所有类。
java.lang.reflect
Java 1.1 中, Class 类(本章前面已有详细论述)得到了扩展,可以支持“反射”的概念
可用构建器创建新对象,用 get()和 set()方法读取和修改与 Field 对象关联的字段,以及用 invoke()方法调用与 Method 对象关联的方法。
所以 RTTI 和“反射”之间唯一的区别就是对 RTTI 来说,编译器会在编译期打开和检查.class 文件。 但对“反射”来说, .class 文件在编译期间是不可使用的,而是由运行期环境打开和检查。
12-传递和返回对象
Java 中每个对象(除基本数据类型以外)的标识符都属于指针的一种
- 参数传递过程中会自动产生别名问题
- 不存在本地对象,只有本地句柄
- 句柄有自己的作用域,而对象没有
- 对象的“存在时间”在 Java 里不是个问题
- 没有语言上的支持(如常量)可防止对象被修改(以避免别名的副作用)
Java 不可能在衍生后反而缩小方法的访问范围。
一旦对象变得可以克隆,从它衍生的任何东西都是能够克隆的。
clone()方法在基础类 Object里为protected(“按位”复制)。
总之,如果希望一个类能够克隆,那么:
- 实现 Cloneable 接口
- 覆盖 clone()
- 在自己的 clone()中调用 super.clone()
- 在自己的 clone()中捕获违例
只要没有新增需要克隆的句柄,对 Object.clone()的一个调用就能完成所有必要的复制—— 无论 clone()是在层次结构多深的一级定义的。
为消除克隆能力,大家也许认为只需将 clone()方法简单地设为private(私有)即可,但这样是行不通的,因为不能采用一个基础类方法,并使其在衍生类中更“私有”。
“关闭”克隆:在衍生类 clone()中,我们掷出CloneNotSupportedException违例。 假如 clone()在 final 类中掷出了一个违例,便不能通过继承来进行修改,并可有效地禁止克隆。因此,只要制作一些涉及安全问题的对象,就最好把那些类设为 final。
14-多线程
创建一个线程,最简单的方法就是从 Thread 类继承。调用start(),它的作用是对线程进行特殊的初始化,然后调用 run()。
对于垃圾收集来说,每个线程都会“注册”自己,所以某处实际存在着对它的一个引用。
接口 Runnable ,其中包含了与 Thread 一致的基本方法。事实上, Thread 也实现了 Runnable ,它只指出有一个 run()方法。
- 一旦所有非 Daemon 线程完成,程序也会中止运行。
- 通过调用 isDaemon(),可调查一个线程是不是一个Daemon,而且能用 setDaemon()打开或者关闭一个线程的Daemon 状态。
- 如果是一个 Daemon 线程,那么它创建的任何线程也会自动具备 Daemon属性
调用任何 synchronized 方法时,对象就会被锁定,不可再调用那个对象的其他任何synchronized 方法
每个类也有自己的一把锁(作为类的 Class 对象的一部分),所以synchronized static 方法可在一个类的范围内被相互间锁定起来。
对于访问某个关键共享资源的所有方法,都必须把它们设为 synchronized,否则就不能正常地工作
synchronized(syncObject) {
// This code can be accessed by only
// one thread at a time, assuming all
// threads respect syncObject's lock
}
synchronized 不能继承—— 也就是说,假如一个方法在基础类中是“同步”的,那么在衍生类过载版本中,它不会自动进入“同步”状态。
一个线程可以有四种状态:
- 新( New):线程对象已经创建,但尚未启动,所以不可运行。
- 可运行( Runnable ):意味着一旦时间分片机制有空闲的 CPU 周期提供给一个线程,那个线程便可立即开始运行。因此,线程可能在、也可能不在运行当中,但一旦条件许可,没有什么能阻止它的运行—— 它既没有“死”掉,也未被“堵塞”。
- 死( Dead):从自己的 run()方法中返回后,一个线程便已“死”掉。亦可调用 stop()令其死掉,但会产生一个违例——属于 Error 的一个子类(也就是说,我们通常不捕获它)。记住一个违例的“掷”出应当是一个特殊事件,而不是正常程序运行的一部分。所以不建议你使用 stop()(在 Java 1.2 则是坚决反对)。另外还有一个 destroy()方法(它永远不会实现),应该尽可能地避免调用它,因为它非常武断,根本不会解除对象的锁定。
- 堵塞( Blocked):线程可以运行,但有某种东西阻碍了它。若线程处于堵塞状态,调度机制可以简单地跳过它,不给它分配任何 CPU 时间。除非线程再次进入“可运行”状态,否则不会采取任何操作。
线程被堵塞可能是由下述五方面的原因造成的:
- 调用 sleep(毫秒数),使线程进入“睡眠”状态。在规定的时间内,这个线程是不会运行的。
- 用 suspend()暂停了线程的执行。除非线程收到 resume()消息,否则不会返回“可运行”状态。
- 用 wait()暂停了线程的执行。除非线程收到 nofify()或者 notifyAll()消息,否则不会变成“可运行”(是的,这看起来同原因 2 非常相象,但wait会释放锁)。
- 线程正在等候一些 IO(输入输出)操作完成。
- 线程试图调用另一个对象的“同步”方法,但那个对象处于锁定状态,暂时无法使用。
- Thread 类提供了一个名为suspend()的方法,可临时中止线程;以及一个名为 resume() 的方法,用于从暂停处开始恢复线程的执行。
- 无论 sleep()还是 suspend()都不会在自己被调用的时候解除锁定
- wait()在挂起内部调用的方法时,会解除对象的锁定。
- wait()和 notify()比较特别的一个地方是这两个方法都属于基础类 Object 的一部分。
能调用 wait()的唯一地方是在一个同步的方法或代码块内部。 若在一个不同步的方法内调用wait()或者 notify(),尽管程序仍然会编译,但在运行它的时候,就会得到一个IllegalMonitorStateException(非法监视器状态违例)。
wait()允许我们将线程置入“睡眠”状态,同时又“积极”地等待条件发生改变。而且只有在一个 notify()或 notifyAll()发生变化的时候,线程才会被唤醒,并检查条件是否有变。因此,我们认为它提供了在线程间进行同步的一种手段。
反对使用 stop(),是因为它不安全。它会解除由线程获取的所有锁定,而且如果对象处于一种不连贯状态(“被破坏”),那么其他线程能在那种状态下检查和修改它们。结果便造成了一种微妙的局面,我们很难检查出真正的问题所在。
- 用一个标志告诉线程什么时候通过退出自己的 run()方法来中止自己的执行。
- 换用由 Thread 提供的 interrupt()方法
如果文章对您有帮助,欢迎扫描下方二维码赞助(一分也是爱噢),谢谢

